
 English
English

Edellisessä tämän kaksiosaisen blogisarjan tekstissä käsittelimme sitä, mitkä ovat pilvisovelluskehityksen hyvät arkkitehtuurikäytännöt. Perehdyimme erityisesti kolmen suurimman palveluntarjoajan, Amazon Web Servicesin, Microsoft Azuren ja Google Cloud Platformin arkkitehtuurisuosituksiin.
Kun pilven parhaat käytännöt ovat hallussa, voidaan syventyä tarkemmin siihen, mitä palveluja nämä pilvialustat tarjoavat käyttöön ohjelmistokehittäjille. Erityisesti keskitytään siihen, mitkä niistä ovat tärkeitä web-ohjelmistokehityksen näkökulmasta. Aloittelevalle pilviohjelmistokehittäjälle voi satojen palvelujen tarjonnan keskellä olla hämmentävää, mikä hänelle on olennaista. Tässä tekstissä tutkitaankin, mitä palveluita voidaan hyödyntää yksinkertaisen mutta skaalautuvan web-applikaation pystyttämiseen.
Palveluja ja palvelimia
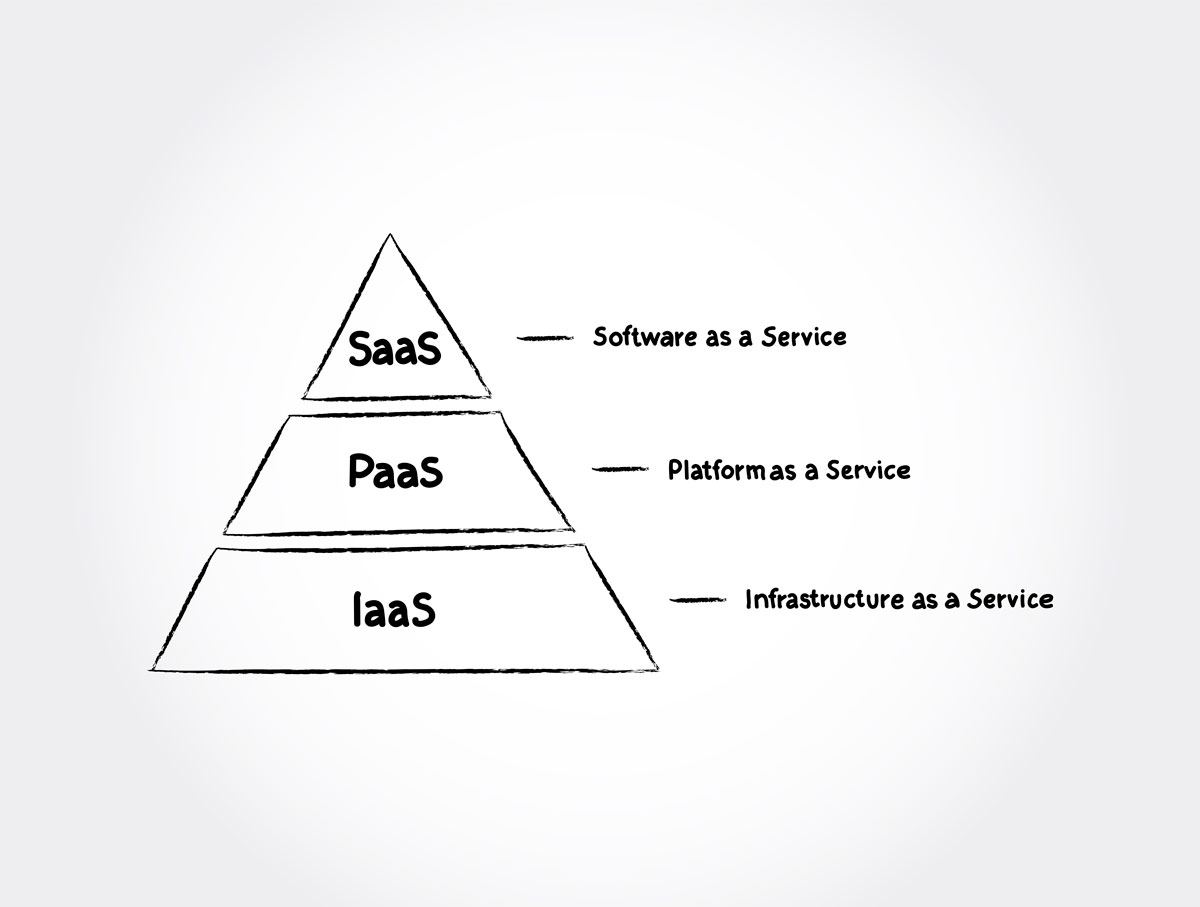
Yksi ensimmäisistä kysymyksistä web-sovellusta pilveen kehitettäessä on, minkä palvelun varaan varsinainen web-palvelin toteutetaan. Pilvialustat mahdollistavat tähän useita ratkaisuja, jotka voidaan jakaa karkeasti ainakin neljään kategoriaan: täysin manageroituun PaaS-applikaatiopalveluun, virtuaalikoneisiin, Docker-kontteihin sekä FaaS-palveluihin.
PaaS
Niin AWS:ssä, Azuressa kuin GCP:ssäkin helpoin tapa saada oma koodinsa pyörimään pilvessä on käyttää alustojen tarjoamia PaaS- eli Platform as a Service -palveluja. Ne hoitavat kehittäjän puolesta sovelluksen tuotantoonsaattamisen, skaalaamisen, kuormantasaamisen ja monitoroinnin, mutta hyödyntävät taustalla pilvipalvelun infrastruktuuria. AWS:n tarjoama PaaS-palvelu on nimeltään AWS Elastic Beanstalk, Azuren Azure App Service ja GCP:n Google App Engine.
PaaS-palvelujen etu on siinä, että ne vaativat vähiten osaamista ja niillä on nopea päästä alkuun. Siksi ne soveltuvat esimerkiksi prototyypitykseen, sekundääristen yksinkertaisten palvelujen toteutukseen tai vaikkapa MVP-tuotteen nopeaan kehitykseen.
Kääntöpuolena PaaS-palvelut ottavat aina jossain määrin pois kontrollia kehittäjältä muun muassa tuotantoonsaattamisen yksityiskohtien, palvelualustan konfiguroitavuuden tai ajoympäristön ohjelmistoversioiden suhteen. Ne voivat asettaa myös rajoituksia sovellukselle esimerkiksi käytettävien ohjelmointikielien suhteen. Kun sovelluksen tiedetään olevan monimutkainen, jakautuvan useisiin mikropalveluihin, ajavan monia taustaprosesseja, vaativan paljon kontrollia sen ympäristöön tai edellyttävän korkeaa saavutettavuutta (high availability), PaaS-palvelut eivät välttämättä ole oikea ratkaisu.
Eri pilvialustojen PaaS-palveluiden välillä on eroa siinä, kuinka paljon ne rajoittavat käyttäjäkontrollia. Esimerkiksi Beanstalk on käytännössä vain ohut hallinnointikerros AWS:n muiden palveluiden päälle, ja käyttäjällä säilyy niihin täysi kontrolli. Azure App Service ja Google App Engine taas asettavat sovelluksen hallinnoinnille enemmän rajoitteita.
Virtuaalipalvelimet
Klassisin tapa toteuttaa sovellus pilveen on epäilemättä hyödyntää vuokrattavia virtuaalipalvelimia. Nämä palvelimet ovat virtuaalikoneita, jotka ajautuvat pilvialustan kiinteän palvelininfran päällä automaattisesti ylläpidettyinä. Varsinaiseen virtuaalikoneeseen, sen asetuksiin sekä sen sisältämään käyttöjärjestelmään ja ohjelmistoihin kehittäjällä on kuitenkin täysi hallinta. Kyseessä on siis IaaS- eli Infrastructure as a Service -palvelu. AWS:n virtuaalikonepalvelu tunnetaan nimellä EC2 (Elastic Compute Cloud), Azuren Azure Virtual Machines ja GCP:n nimellä Google Compute Engine.
Virtuaalipalvelimet antavat kehittäjälle eniten hallintaa ohjelman ajoympäristöön. Ne ovat suositeltavia silloin, kun sovellus vaatii tarkkaa kontrollia esimerkiksi käyttöjärjestelmään, prosessoriin, I/O:hon, näytönohjaimeen tai muistiin. Samalla niistä syntyy kuitenkin kehittäjille eniten työtä ympäristön hallinnoinnin muodossa, sillä koko palvelintietokone on käyttäjän vastuulla.

Virtuaalipalvelimet ovat tavanomaisesti olleet pilviohjelmistokehityksessä oletusvaihtoehto, jonka varaan sovellus kehitetään. AWS:n ja Azuren tapauksessa ne ovat myös edelleen yleisesti käytetyin vaihtoehto.
Virtuaalipalvelimia skaalataan tavanomaisesti autoskaalausryhmien avulla, joita sivuttiin edellisessä blogitekstissä. Autoskaalaus pyrkii pitämään tietyn virtuaalikoneiden joukon toimintakykyisenä, vaikka käyttäjämäärä kasvaisi tai jokin palvelimista kaatuisi. Se saavuttaa tämän skaalaamalla palvelininstanssien määrää ylös- tai alaspäin erilaisten asetettujen ehtojen mukaisesti.
Docker-kontit
Pilvimaailma on siirtymässä virtuaalikoneista kuitenkin vähitellen kohti konttien ja serverless-mallien hyödyntämistä. Docker-kontit ovat jo varsin yleinen tapa toteuttaa palvelinsovellus pilveen: pilvipalvelu hoitaa kaiken alla olevan infran ja käyttöjärjestelmän pyörittämisen, kehittäjän tarvitsee huolehtia vain itse konteista ja niiden sisältämästä ohjelmistosta. Sovelluskehittäjän kannattaakin miettiä tarkkaan, edellyttävätkö hänen tarpeensa välttämättä kokonaisten virtuaalikoneiden hallinnointia vai voisiko työmäärää säästää ulkoistamalla käyttöjärjestelmän hallinnoinnin pilvialustan tehtäväksi.
GCP suosittelee esimerkiksi Cloud Run -konttiajopalveluaan jo sovellusten oletustoteutusvaihtoehtona virtuaalikoneiden sijaan. Myös Azure tarjoaa vaihtoehdon isännöidä yksittäisiä kontteja pilvessä Azure Container Instances -palvelullaan.
AWS:ssä taas konttien hallinnointi tapahtuu aina joko Elastic Container Service– tai Kubernetes-orkestrointipalvelujen kautta. ECS on AWS:n oma palvelu, kun taas Kubernetes jonkin verran monimutkaisempi, pilvialustariippumaton palvelu, josta AWS tarjoaa myös hallinnoidun version. Nämä molemmat on tarkoitettu konttipohjaisten mirkopalvelusovellusten skaalaamiseen ja hallintaan. Ne voivat ajaa kontteja EC2-virtuaalikoneiden päällä, joita käyttäjä joutuu itse ylläpitämään, tai hyödyntäen AWS:n Fargate -palvelua, jolloin kontit ajautuvat serverless-moodissa. Fargaten tapauksessa kehittäjän ei tarvitse välittää konttien alla olevista virtuaalikoneista vaan AWS hallinnoi niitä automaattisesti konepellin alla.

Myös muut pilvialustat tarjoavat kehittäjälle käyttöön Kuberneteksen monimutkaisempaan mikropalvelusovelluksen konttiorkestrointiin. Azurella on lisäksi oma hallinnoitu ja helpotettu Azure Container Apps -palvelunsa, joka rakentuu Kuberneteksen päälle. Kaikkien palvelualustojen tapauksessa kehittäjä pystyy toki myös manuaalisesti käynnistämään kontteja pilvipalvelualustalta tilattuihin virtuaalikone-instansseihin.
FaaS-palvelut
PaaS-tyyppisten automaattisesti hallinnoitujen sovelluskehityspalvelujen sekä IaaS-tyyppisten virtuaalikone- ja konttipalveluiden lisäksi pilvialustat tarjoavat FaaS- eli Function as a Service -tyyppisiä serverless-palveluita. Näitä ovat muun muassa AWS Lambda, Azure Functions sekä GCP:n Cloud Functions. Näihin palveluihin viitataan yleisimmin, kun puhutaan pilven yhteydessä serverlessistä, vaikka myös esimerkiksi kontteja voi ajaa pilvessä serverlessinä.
FaaS-palvelut soveltuvat parhaiten tapauksiin, jossa pilveen tarvitsee toteuttaa funktion kaltainen operaatio tai sovellus, joka ajautuu yhtenä taskina. Tällaisia voivat olla muun muassa datan konvertoiminen muodosta toiseen, sen noutaminen ja validointi tietystä ulkoisesta lähteestä tai vaikkapa web-tokenin verifiointi.
Mikään ei estä koko backendinkään toteuttamista pelkkinä serverless-funktioina, jos palvelimella ajettavat taskit ovat vain suhteellisen kevyitä, riippumattomia, tilattomia eivätkä pidä sisällään taustalla suoriutuvia operaatioita. Tämä voi olla toimiva ratkaisu erityisesti, kun kysymyksessä on esimerkiksi rajallisen kokoinen mikropalvelu. Kääntöpuolena täytyy tosin pitää tarkkaan huolta, ettei sovelluskoodi tule liian tiukkaan naitettua yhteen kulloinkin käytössä olevan palveluntarjoajan ja FaaS-palvelun kanssa.
Kun serverless-funktion varaan rakennetaan backend-operaatio ja se halutaan paljastaa julkiseksi Internetiin päin, tavanomaisesti funktion yhteydessä käytetään pilvialustan manageroimaa API-palvelua. Näitä rajapintapalveluja ovat Amazon API Gateway, Azure API Management sekä GCP:n API Gateway. Ne mahdollistavat esimerkiksi REST-rajapinnan sekä AWS:n ja Azuren tapauksessa myös Websocket-rajapintojen toteuttamisen pilvialustan isännöimänä ja automaattisesti hallinnoimana.

Rajapinta voi puolestaan asettaa kunkin backendin serverless-funktion eteen Internetiin julkisen päätepisteen (endpoint), johon funktiolle osoitetut pyynnöt saapuvat. API-palveluita voi käyttää myös Docker-konttien ja virtuaalikoneiden yhteydessä, mutta tällöin kehittäjän on jälleen tehtävä päätös, haluaako hän tehdä API-toteutuksestaan riippuvaisen juuri tietyn pilvialustan palvelusta.
Tietoa kantaan
Pilvipalveluissa tietokantoja on lukemattomia erilaisia ja erityyppisiä. Kolmannen osapuolen tietokannoista on puolestaan saatavilla sekä automaattisesti hallinnoituja että hallinnoimattomia versioita. Kehittäjän on myös aluksi hyvä ymmärtää tietokantojen kohdalla erot relaatiotietokantojen ja NoSQL-kantojen välillä.
Relaatiotietokannat
Tietokantatyyppien kategorisoinnissa tehdään yleensä jako relaatio- ja NoSQL-kantojen välillä. Relaatiotietokannalla tarkoitetaan perinteistä tietokantaa, joka toimii niin sanotun relaatiomallin pohjalta. Se on hyvä valinta tietokantatyypiksi valtaosaan käyttötapauksista.
Relaatiotietokannalle perustavanlaatuinen piirre on datan jaottelu sarakkeista ja riveistä koostuviin tauluihin, joissa jokaisen rivin yksilöi uniikki avain. Näiden avainten pohjalta taulujen välille pystytään muodostamaan myös suhteita eli relaatioita. Tällaisiin kantoihin kyselykielenä toimii tyypillisesti SQL-kieli, ja ne ovat usein tehokkaita hakujen ja lukemisen suhteen.

Pilvialustat tarjoavat suosituimpia relaatiotietokantoja käyttöön hallinnoituina versioina. Esimerkiksi kaikki kolme suurinta pilvipalveluntarjoajaa mahdollistavat PostgreSQL-, MySQL- sekä SQL Server -tietokantojen käytön manageroituna palveluna. Näitä palveluita, jotka mahdollistavat relaatiotietokannan automatisoidun hallinnoinnin ovat nimeltään Amazon Relational Database Service (RDS), Azure SQL Database sekä GCP:n Cloud SQL.
Relaatiotietokantoja on mahdollista ajaa myös serverless-moodissa. AWS tarjoaa MySQL- ja PostgreSQL-kannoista pilvioptimoidun Amazon Aurora -version, joka ajautuu serverlessinä automaattisin replikoinnein ja varmuuskopioinnein. Azure SQL Database tarjoaa myös serverless-moodin, jolloin tietokantaa skaalataan automaattisesti ja sen toiminta keskeytetään silloin, kun aktiviteetteja ei ole. GCP ja Cloud SQL eivät tällä hetkellä tarjoa vastaavaa ominaisuutta.
Perinteisiä relaatiotietokantoja on tietysti mahdollista ylläpitää pilvessä myös itse, esimerkiksi virtuaalikoneelle asennettuna tai kontitettuna. Tällöin niiden managerointi jää käyttäjän omalle vastuulle, mutta lopputuloksena voi koitua käyttötapauksesta riippuen hintasäästöä.
NoSQL-kannat
NoSQL-kannoiksi lasketaan kaikki relaatiotietokantoihin kuulumattomat kannat. Ne eivät siis noudata relaatiomallia. Nämä jaotellaan tavanomaisesti neljään tyyppiin: avain-arvokantoihin, saraketietokantoihin, graafipohjaisiin kantoihin sekä dokumenttitietokantoihin. Myös muistitietokannat ja tietovarastot (data warehouse) kuuluvat yleensä johonkin näistä.
Kaikilla kolmella pilvialustalla on käytännössä yksi vain kyseisen alustan tarjoama, laajasti käytetty serverlessinä toimiva, automaattisesti skaalautuva NoSQL-kanta, jota ne markkinoivat vahvasti käyttäjilleen. AWS:llä se on DynamoDB, joka on avain-arvo-tietokanta. Azuressa käytetyin on taas useata tietomallia tukeva CosmosDB. GCP:n oma NoSQL-ratkaisu on puolestaan BigTable, sekin avain-arvo-tietokanta, joka on rakennettu Apache HBase -kannan kanssa yhteensopivaksi.

DynamoDB ja BigTable soveltuvat todella nopeita luku- ja kirjoitusnopeutta sekä skaalautuvuutta kaipaaville sovelluksille. Ne eivät kuitenkaan sovi hyvin monimutkaisten kyselyjen toteuttamiseen datalle, jolla on paljon riippuvuuksia keskenään. Ne eivät myöskään käytä SQL:ää kyselykielenään vaan kyselyissä hyödynnetään tietokannan tarjoamaa ohjelmointirajapintaa. DynamoDB mahdollistaa kuitenkin nykyään SQL-yhteensopivan PartiQL-kielen hyödyntämisen kyselyihin.
CosmosDB sisältää rajapinnat monenlaisten eri datamuotojen tallentamiseksi ja kyselemiseksi. Se on samankaltainen palvelu NoSQL-kannoille kuin esimerkiksi Amazon Aurora on relaatiotietokannoille. Se tarjoaa optimoidun, automaattisesti skaalautuvan ja hallinnoidun serverless-mallisen rajapinnan eri NoSQL-tietokantamoottoreille, kuten MongoDB:lle, Cassandralle sekä Azuren omalle taulutietokannalle Azure Tablelle, joka pystyy varastoimaan ei-relationaalista strukturoitua dataa. Vaikka kyseessä on NoSQL-kanta, erikoisuutena se tukee myös SQL:ää. Lisäksi se sisältää rajapinnan graafitietokannoille tarkoitetulle Gremlin-kyselykielelle.
Azure suosittelee CosmosDB:ää muun muassa web- ja IoT-sovelluksille, jotka tarvitsevat automaattista skaalautuvuutta, jatkuvaa saavutettavuutta sekä korkeaa luku- ja kirjoitusnopeutta. Se soveltuu esimerkiksi web-kehittäjille, jotka ovat tottuneet MongoDB:hen tietokantaratkaisuna. Palveluna CosmosDB on kuitenkin kohtalaisen hintava.
Myös AWS ja GCP tarjoavat omat versionsa hallinnoiduista dokumenttitietokannoista. Palvelualustojen dokumenttitietokannat ovat nimeltään Amazon DocumentDB sekä GCP:llä Cloud Firestore. AWS DocumentDB on enimmäkseen MongoDB 4.0 -yhteensopiva. Lisäksi kaikilla kolmella pilvialustalla on mahdollista ajaa MongoDB:tä manageroituna palveluna MongoDB Atlas -palvelun kautta.

Pilvialustojen omien tietokantojen suhteen kannattaa huomioida, että niitä käytettäessä ohjelmisto voi muodostua sitä herkemmin riippuvaiseksi kyseisestä palveluntarjoajasta, mitä vahvemmin kanta on sidoksissa nimenomaan kyseiseen alustaan. Esimerkiksi DynamoDB on nimenomaisesti AWS-palvelu, jonka rajapintaa pitää käsitellä kyseiselle kannalle erikoistuneesti. Jos sovelluksen rajapinta taas on yhteensopiva jonkin alustariippumattoman kannan kanssa, kuten CosmosDB:n tai AWS DocumentDB:n tapauksessa, migraatio toiseen pilvipalveluntarjoajaan voi olla helpompaa.
Toiseksi luotettavien paikallisten testien toteuttaminen pilvialustojen omien kantojen ympärille voi olla haastavaa. Usein testaamiseen tarkoitetut lokaalit kantaversiot nimittäin vain emuloivat varsinaista pilvikantaa, jolloin eroavaisuuksia toiminnassa löytyy.
NoSQL-kantoja, kuten MongoDB:n tai Cassandran, pystyy luonnollisesti asentamaan myös manuaalisesti pilvestä tilatuille virtuaalipalvemille. Kuten relaatiotietokantojen kohdalla, tällöin vastuu kaikesta hallinnoinnista jää itse käyttäjälle.
Pilvipalvelujen muista NoSQL-kannoista mainittakoon lyhyesti myös välimuistiratkaisuna tavanomaisesti käytetyt muistitietokannat, joita edustavat muun muassa Amazon ElastiCache, Azure Cache for Redis ja GCP:n Memorystore. Samoin maininnan ansaitsevat tietovarastot, jotka kokoavat dataa useasta lähteistä analytiikkaa varten. Näihin kuuluvat esimerkiksi Amazon Redshift, Azure Synapse Analytics sekä GCP:n BigQuery.
Sisältö jakoon
Erityisesti web-sovelluksia kehittäessä syntyy usein tarve palvella käyttäjille paljon staattista dataa, kuten kuvia, ääntä ja videoita. Lisäksi sovellukset tuottavat tavanomaisesti suuret määrät esimerkiksi lokidataa. Kaikelle tälle datalle pitää siis olla jonkinlainen varasto, johon sitä tallennetaan ja josta sitä tarvittaessa myös saatetaan jakoon.
Tietovarastot
Ensimmäisenä kysymyksenä saattaa herätä luonnollisesti, miksei tiedostoja voisi tallentaa vain vaikkapa virtuaalikoneille, jossa palvelinohjelmisto ajautuu. Tällöin kuitenkin pilvisovelluksen käyttäjä joutuisi itse varmistamaan, että koneiden kiintolevytila säilyy riittävänä, virtuaalikone-instanssit skaalautuvat datankäsittelyn tarpeisiin, levyjen sisältöä varmuuskopioidaan tasaisin väliajoin ja että dataa replikoidaan kaikille palvelimille, jotka sitä tarvitsevat. Tämä on tietysti mahdollista mutta epäkäytännöllistä.

Kaikki pilvialustat mahdollistavat tietysti nopeiden kiintolevyjen liittämisen virtuaalikoneisiin niin sanottuina lohkovarastopalveluina (block storage). Näitä palveluita ovat muun muassa Amazon EBS (Elastic Block Storage), Azure Disk Storage sekä GCP:n Persistent Disk.
Kiintolevyjen manuaalisen hallinnoinnin ohella kaikki kolme pilvialustaa tarjoavat kuitenkin automaattisesti skaalautuvan, serverlessinä toimivan, kestävän, korkean saavutettavuuden tietoturvallisen objektitietovarastopalvelun, joka on hinnaltaan tavanomaisesti halvempi kuin lohkovarasto. Näitä tietovarastoja ovat Amazon S3 (Simple Storage Service), Azure Blob Storage sekä GCP:n Cloud Storage.
Objektitietovarastoille ominaista on se, että niistä puuttuu tiedostojärjestelmän hierarkia: objektit tallennetaan objektitietovarastoon tasaisesti avain-arvo-pareina. Tietoa voidaan tallentaa tiedostojen sijaan myös vaikkapa serialisoituna objektina ilman tiedostometadataa. Näitä tietovarastoja käsitellään rajapinnan kautta HTTP:n ylitse, ja objekteja voidaan palvella myös loppukäyttäjälle verkon välityksellä.
Vaihtoehto objektitietovarastoille on tiedostojärjestelmäpalvelu. Kaikki kolme pilvialustaa tarjoavat tällaisen oman serverless-palvelun, joka objektititietovaraston tavoin on automaattisesti skaalautuva, kestävä, tietoturvallinen ja takaa korkean saavutettavuuden. Näitä tiedostojärjestelmäpalveluja ovat Amazon EFS (Elastic File System), Azure Files sekä GCP:n Filestore.
Tiedostojärjestelmä käyttää HTTP:n sijaan tiedostojärjestelmäprotokollaa, esimerkiksi NFS:ää, joten käsittely on hyvin nopeaa. Se myös sisältää tavanomaisen tiedostojärjestelmän hierarkian ja siihen tallennetaan vain tiedostoja. Virtuaalikoneet liittyvät (mount) tiedostojärjestelmään, joten sitä voidaan käsitellä suoraan virtuaalikoneesta käsin kuin mitä tahansa tiedostojärjestelmän osaa. Sama tiedostojärjestelmä voidaan jakaa myös lukuisten virtuaalikoneiden kesken, mikä voi olla hyödyllistä esimerkiksi big data -analyysissa suurien tiedostomäärien hajautettuun käsittelyyn.

Nyrkkisääntönä staattiselle datalle oletusvaihtoehto tietovarastoksi pilvessä on tavanomaisesti objektitietovarasto, erityisesti jos dataa on tarkoitus palvella ulospäin. Tämä on myös kaikkein halvin vaihtoehto. Jos kehitettävä ohjelmisto tarvitsee nimenomaisesti hajautetun tiedostohierarkian suurelle määrälle tiedostoja tai vaatii suurta tiedostokäsittelynopeutta esimerkiksi analytiikkatarpeisiin, tiedostojärjestelmäpalvelu on varteen otettava vaihtoehto. Jos puolestaan sovellus tarvitsee nimenomaisesti tietovarastoa yksittäiselle virtuaalikoneelle eikä skaalautuminen ole merkittävä tekijä, tulevat kysymykseen lohkovarastot.
Sisällönjakeluverkot
Staattisia tiedostoja on mahdollista palvella ulospäin esimerkiksi objektitietovarastosta tai tiedostojärjestelmästä. Kun sovellus kuitenkin toimii globaalisti, jakelee paljon staattisia tiedostoja ja vaatii käyttäjäystävällisiä tiedonsiirtonopeuksia, kysymykseen voi tulla sisällönjakeluverkko. Sisällönjakeluverkko on maantieteellisesti hajautettu verkko, joka koostuu välityspalvelimista. Se tarjoaa staattista dataa, kuten kuvia, videota ja ääntä lähellä loppukäyttäjää, pienin viivein sekä suurella toimintavarmuudella.
Kolmen suurimman pilvialustan tarjoamat sisällönjakeluverkot ovat nimeltään Amazon CloudFront, Azure CDN ja GCP:n Cloud CDN. Ne pystyvät palvelemaan sekä tallentamaan välimuistiin niin staattista kuin dynaamista dataa eri HTTP-lähteistä, kuten tietovarastoista tai virtuaalikoneilta, joilla palvelinsovellus ajautuu. Luonnollisesti niiden kääntöpuolena on ylimääräinen hinta, jota pilvisovelluksen ylläpitäjä joutuu maksamaan sisällönjakeluverkon käytöstä.
Oikeudet kuntoon
Web-sovelluksia kehittäessä tavanomaista on, että sovellus vaatii jonkinlaisen menetelmän käyttäjien autentikointiin. Autentikoinnilla viitataan käyttäjän identiteetin tunnistamiseen ja varmentamiseen, käytännössä sisäänkirjautumisen sekä sen jälkeen tapahtuvien palvelinpyyntöjen yhteydessä.

Kaikki kolme suurinta pilvialustaa tarjoavat palvelun tämän tehtävän toteuttamiseen. Kyseiset palvelut ovat Amazon Cognito, Azure Active Directory B2C sekä Googlen Identity Platform. Viimeistä ei kannata sekoittaa Cloud Identityyn, joka tarjoaa SSO:n (single sign-on) ja MFA:n (multi-factor authentication) useisiin SaaS-sovelluksiin esimerkiksi yrityksen työntekijöille.
Yllä mainitut kolme palvelua tarjoavat pilvisovellukselle skaalautuvan ja tietoturvallisen tavan autentikoitua sovellukseen. Ne hallinnoivat sovelluksen käyttäjäprofiileja, joille myönnetään oikeuksia sovelluksen resursseihin. Ne myös hoitavat pilvikehittäjän puolesta sisäänkirjautumisen, salasanojen hallinnoinnin, MFA:n toteuttamisen sekä autentikaatio-tokenit. Sisäänkirjautuminen voidaan hoitaa niiden kautta myös kolmannen osapuolen käyttäjätunnuksilla, jolloin autentikaatiopalvelu pitää huolta tähän liittyvistä protokollista.
Siinä missä Azure AD B2C ja Google Identity Platform keskittyvät lähinnä autentikointiin, AWS Cognitolla on myös mahdollista hoitaa käyttäjien autorisointi eli oikeuksien myöntäminen AWS-resursseihin, kuten vaikkapa S3:een tallennettuihin tiedostokokoelmiin tai DynamoDB-tauluihin. Tämä tapahtuu Cogniton identiteettipoolien (identity pool) avulla, jotka yhdistävät käyttäjän AWS:n sisäisen IAM- eli Identity and Access Management -palvelun rooleihin. Näin käyttäjä saa väliaikaisen oikeuden kyseisen roolin sallimiin AWS-resursseihin.
Pilvisovelluskehittäjä pystyy luonnollisesti toteuttamaan autentikoinnin sovellukseensa myös itse ilman pilvialustan tarjoamia erillisiä palveluita. Tällöin säästönä on palvelun hinta, mutta luonnollisesti kehittäjän vastuulle jää kirjautumisen, käyttäjätunnusten, salasanojen, tokenien tai cookieiden hallinnan sekä MFA:n toteuttaminen. Toisaalta tämä antaa enemmän kontrollia kehittäjälle autentikaation toteuttamiseen eikä se muodostu riippuvaiseksi itse pilvialustasta.
Liikenne hallintaan
Jotta web-sovellus voidaan saattaa julkiseksi tuotantoon tietyn domain-nimen alaisuuteen, pitää käyttöön ottaa DNS-palvelu, joka reitittää liikennettä domain-nimen pohjalta. Lisäksi sovellukselle saapuvan liikenteen hallintaan äärimmäisen hyödyllinen palvelu on kuormantasaaja (load balancer), joka pystyy jakamaan liikennettä sovelluksen palvelininstanssien, kuten virtuaalikoneiden tai konttien välillä.
DNS-palvelut
DNS-palvelun tehtävä on rekisteröidä ja hallinnoida domaineja. Sillä luodaan myös DNS-tietueita (DNS record), joilla mapataan domaineja ja alidomaineja sovelluksen IP-osoitteisiin tai pilvipalveluihin. Lisäksi ne toteutettavat liikenteen hallintaa ja seuraavat tietueiden terveyttä säännöllisesti.
Liikennettä voidaan DNS-palvelussa hallita erilaisin reitityskriteerein. Ne määräävät, miten tiettyyn domainiin kohdistuvaa liikennettä reititetään siihen yhdistettyjen eri IP:iden tai palvelujen välillä.

Kolmen eri pilvialustan DNS-palvelut ovat nimeltään Amazon Route53, Azure DNS sekä Cloud DNS. Luonnollisesti sovelluskehittäjä voi myös ylläpitää pilvessä itse DNS-palvelimia tai rekisteröidä domain-nimensä jonkin kolmannen osapuolen DNS-palvelun, kuten GoDaddyn tai Cloudflaren kautta.
Etu pilvipalveluiden omissa DNS-palveluissa manuaaliseen ylläpitoon nähden on toki se, että palvelun hallinnointi hoidetaan luotettavasti pilvialustan puolesta. Verrattuna kolmannen osapuolen palveluihin, pilvialustojen omat DNS-palvelut puolestaan saattavat helpottaa DNS:n integrointia alustan muiden palveluiden kanssa, kuten Route53:n tapauksessa. Lisäksi DNS:ää hallinnoidaan tällöin saman alustan alaisuudessa samoin käyttäjätunnuksin ja oikeudenhallintamenetelmin kuin muitakin pilvisovellukseen liittyviä palveluja. Lopulliseen valintaan vaikuttavat kuitenkin myös hinta sekä se, tarjoaako DNS-palvelu kaikki sovelluksen kaipaamat ominaisuudet.
Kuormantasaajat
Kuormantasaamisella tarkoitetaan sisääntulevan liikenteen tasaista jakamista backendin palvelimille tai muille resursseille. Kuormantasaaja voi toimia joko Internetin sovelluskerroksessa ja tasata HTTP- ja HTTPS-liikennettä, kuljetuskerroksessa, jolloin se tasaa TCP- ja UDP-liikennettä, tai jopa verkkokerroksessa tasaamassa IP-paketteja. Ne voivat hyödyntää tasaamisessaan terveystarkistuksia sekä uudelleenohjata liikennettä perustuen erilaisiin sääntöihin, esimerkiksi HTTP-headerien perusteella. Niihin voidaan myös liittää palomuureja sekä DDoS-hyökkäysten (Distributed Denial of Service) eli hajautettujen palvelunestohyökkäysten ehkäisypalveluita.
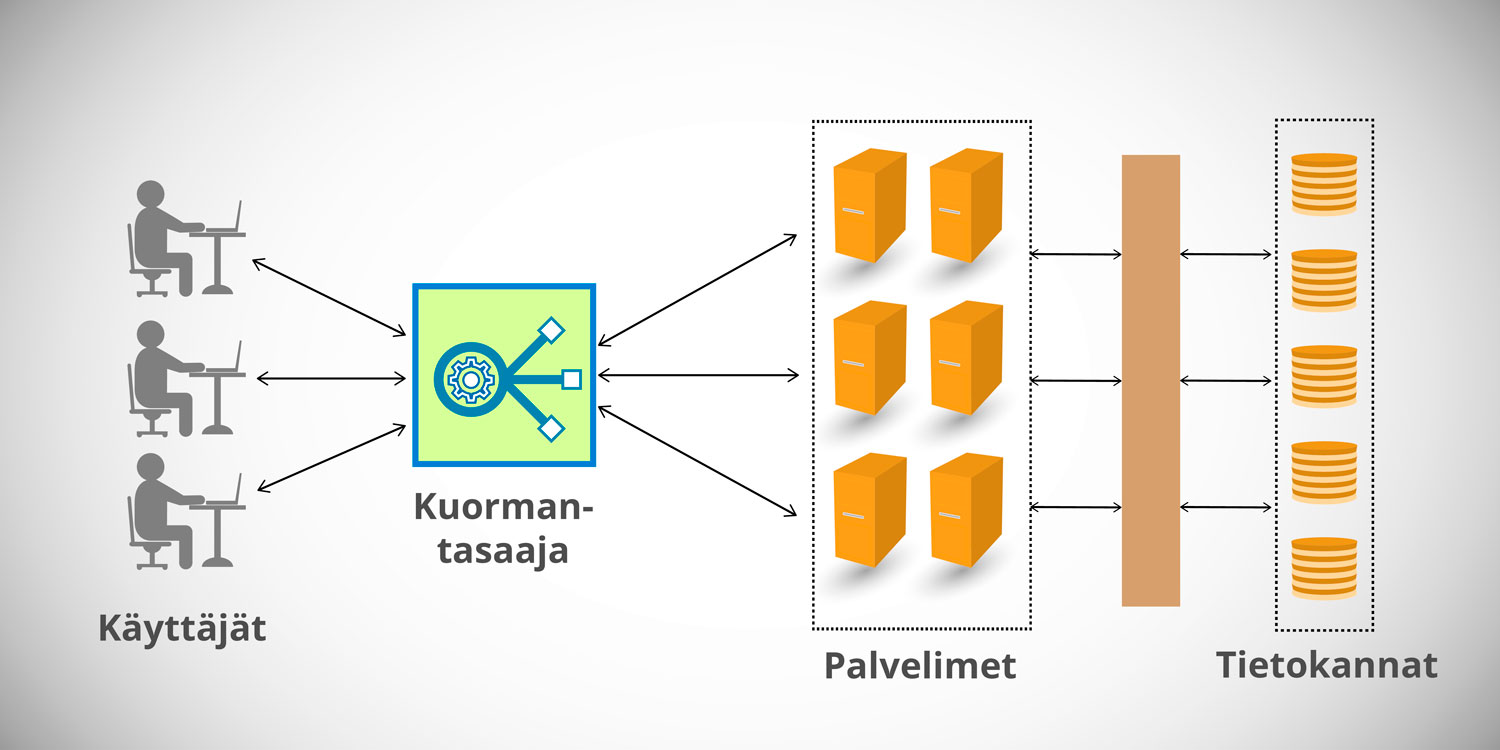
AWS:ssä kuormantasaajapalvelun nimi on Elastic Load Balancing. Sen viimeisin versio pitää sisällään kolme eri kuormantasaajatyyppiä: Application, Network ja Gateway Load Balancerin. Application Load Balancer toimii sovelluskerroksessa ja tasaa HTTP/HTTPS-liikennettä esimerkiksi EC2-autoskaalausryhmän sisällä tai Fargate- ja Kubernetes-klustereissa. Network Load Balancer puolestaan hoitaa kuljetuskerroksessa TCP/UDP-liikenteen, kun taas Gateway Load Balancer tasaa IP-paketteja kolmannen osapuolen palomuurien, tunkeilijanhavaitsemisjärjestelmien, pakettien syväanalyysijärjestelmien sekä muiden virtuaalilaitteiden kesken.
Azuren kuormantasaajia ovat Azure Load Balancer, joka on vastuussa verkon kuljetuskerroksesta ja toimii vastaavasti kuin AWS:n Network Load Balancer, sekä Azure Application Gateway, joka vastaa AWS:n Application Load Balanceria. GCP:n Cloud Load Balancing puolestaan tarjoaa kuormantasaajia, jotka pystyvät toimimaan niin sovellus- kuin kuljetuskerroksessakin.
Eikä siinä vielä kaikki
Tässä blogitekstissä käsitellyt palvelut ovat vasta pintaraapaisu pilvialustojen koko tarjonnasta. Kaikki kolme suurinta alustaa tarjoavat yli sata palvelua, joita olisi mahdotonta käsitellä tiiviisti.
Tekstissä on jätetty mainitsematta kokonaan analytiikkaan, datankeruuseen, hajautettuun palvelukommunikaatioon, big dataan, DevOpsiin, Infrastructure as Codeen, Internet of Thingsiin sekä tekoälyyn liittyvät palvelut. Siinä ei ole myöskään käsitelty viime osassa sivuttuja monitorointi- tai hinta-arviotyökaluja eikä identiteetin ja oikeuksien hallintaa. Isona teemana myös virtuaaliverkkojen hallinta on sivuutettu kokonaan.
Laajempi tutustuminen pilvialustojen palvelutarjontaan ja niiden suomiin mahdollisuuksiin edellyttää itsenäistä perehtymistä sekä lopulta käsien laittamista saveen. Tässä tekstissä on esitelty vain joukko keskeisiä työkaluja, joiden avulla pääsee jo hyvin vauhtiin web-sovelluskehityksessä. Tärkeää onkin kyetä tekemään vertailuja alustojen tarjoamien eri palveluiden ja niiden käyttötarkoitusten välillä.